
Azure Synapse Dedicated SQL-pool (tidigare Azure SQL Data Warehouse), är en massiv parallell bearbetningsdatabas som liknar andra kolumnbaserade, utskalade databastekniker som Snowflake, Amazon Redshift och Google BigQuery.
För slutanvändaren är det ungefär som en traditionell SQL-server, men bakom kulisserna distribuerar den lagring och bearbetning av data över flera noder. Även om detta drastiskt kan förbättra prestandan för datalager större än några få terabyte, kanske det inte är en idealisk lösning för mindre implementeringar. Eftersom den underliggande arkitekturen är så drastiskt annorlunda skiljer sig syntaxen och utvecklingsmetoderna också från traditionell SQL-server.
Att notera, när du använder TimeXtender med Azure Synapse Analytics genereras koden åt dig.
Med det sagt, låt oss titta närmare på problemet genom att titta på kostnaderna.
1. BERÄKNINGS- VS LAGRINGSKOSTNADER
Azure Synapse Analytics hjälper användare att bättre hantera kostnader genom att separera beräkning och lagring av deras data. Användare kan pausa tjänsten och därigenom släppa beräkningsresurserna tillbaka till Azure. När de är pausade debiteras användarna endast för det lagringsutrymme som används (grovt räknat $125 USD/Månad/Terabyte). Under denna tid förblir din data intakt men otillgänglig via frågor. Om du återupptar SQL-poolen omfördelas beräkningsresurserna till ditt konto, och dina data kommer tillbaka online och debiteringarna återupptas.
I likhet med Azure SQL DB:s DTU:er, mäts beräkning i en Synapse SQL Pool av Data Warehouse Units (DWU). Justering av DWU:er kommer att öka eller minska antalet tillgängliga beräkningsnoder såväl som relativ prestanda och kostnad för tjänsten.
2. ARKITEKTUR
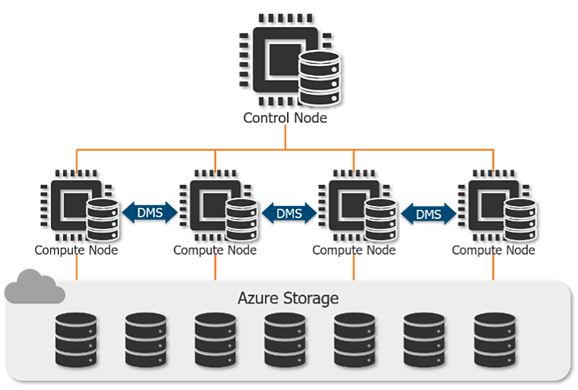
Bearbetning av data i en Synapse SQL Pool är fördelat över många noder av olika typer.
Kontrollnoden accepterar slutanvändarförfrågningar och optimerar och koordinerar sedan dessa frågor så att de körs parallellt över beräkningsnoderna.
Medan en traditionell SQL-databas är beroende av beräkningsresurserna för en enskild maskin, kan en Synapse SQL Pool distribuera bearbetningen av tabeller över upp till 60 beräkningsnoder beroende på servicenivån. Ju fler DWU:er du har tilldelat, desto fler beräkningsnoder kommer att användas.
För att bibehålla dataintegriteten under skalning, underhålls data i Azure Storage separat från kontroll- och beräkningsnoderna. Dessutom, för att ytterligare optimera behandlingen av stora datamängder, sprids tabeller alltid över 60 distributioner (mer om detta i nästa avsnitt).
Data Movement Service (DMS) hanterar förflyttningen av datat över beräkningsnoderna.
3. TABELLFÖRDELNING
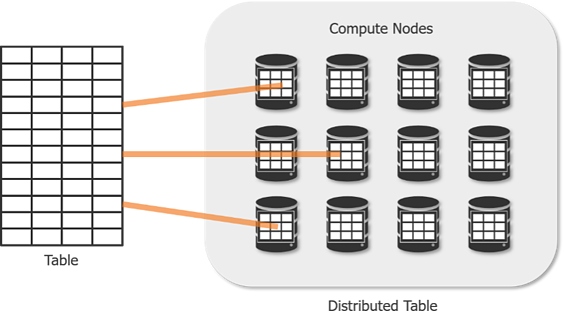
För att balansera bearbetning över många noder delas tabeller upp i 60 distributioner. Denna process är känd som ”skärning”. Distributionsmetoden bestämmer hur rader i en tabell är organiserade över noder.
- Round-robin(standard) – Fördelar rader slumpmässigt jämnt över noder. Ej optimalt för förfrågningsprestanda eftersom det inte finns någon logik i hur data delas. Att sammanfoga round-robin-tabeller kräver ofta att data blandas, vilket tar längre tid.
Detta är idealiskt för uppsättning av tabeller.
- Replicated- Detta replikerar alla rader i tabellen på varje nod. Som du kan föreställa dig är laddningstiderna inte optimala. Men frågorna i den här tabellen är snabba eftersom blandning av data aldrig är nödvändig. Detta är idealiskt för dimensionstabeller som är mindre än 2 GB.
- Hash-rader fördelas över noder med hjälp av en ”fördelningskolumn”. SQL-poolen använder den här kolumnen för att fördela data över noder, och behåller alla rader med samma värde i samma nod. Det här alternativet ger den högsta förfrågningsprestandan för sammanfogningar och aggregering på stora tabeller.
VÄLJA EN DISTRIBUTIONSKOLUMN
För att hjälpa dig välja en distributionskolumn som ger bästa resultat kan du följa dessa riktlinjer.
- Inga uppdateringar- Distributionskolumner kan inte uppdateras.
- Jämn fördelning av värden- För bästa resultat bör alla distributioner ha samma antal rader. Förfrågningar kan bara vara lika snabba som den största distributionen. För att uppnå detta, sikta på kolumner som har:
- Många unika värden- mer unika, större chans att jämna ut distributionen.
- Få eller inga nollor
- Inte en datumkolumn- Om alla användare filtrerar på samma datum, kommer bara en nod att utföra all bearbetning.
- Sammanfoga eller gruppera efter kolumn- Att välja en distributionskolumn som vanligtvis används i en join- eller group by-sats minskar mängden datarörelse för att bearbeta en fråga.
- Om inget bra alternativ – Skapa en sammansatt kolumn med flera sammanfogningskolumner.
NÄR BÖR DU ÖVERVÄGA AZURE SYNAPSE ANALYTICS?
> 1 TB databas — Eftersom tabeller i Azure Synapse alltid är spridda över 60 distributioner, realiseras inte prestandavinster vanligtvis förrän ditt datalager är mer än 1-5 TB. Som en allmän regel kommer datalager på mindre än 1 TB att prestera bättre på Azure SQL DB än på DW.
> 1 Miljard radtabeller — Databasstorlek är inte den enda faktorn att ta hänsyn till. Eftersom distribution sker på tabellnivå om alla dina tabeller är mindre än 100 miljoner rader, kanske du inte ser en betydande prestandaökning från Azure Synapse.
< 128 samtidiga förfrågningar — När SQL-poolen har tagit emot mer än 128 samtidiga förfrågningar kommer den att börja köa dem i en först-in-först-ut-basis. Azure SQL DB och Analysis Services kan stödja många fler samtidiga frågor. För att lösa denna begränsning rekommenderar vi att du matar in data till en Analysis Service Server för större efterfrågan.
DATAWAREHOUSE TUNING
Hur tabeller fördelas bör baseras på hur användare frågar efter data då tillvägagångssättet drastiskt kan påverka prestandan. Så Synapse SQL Pool är inte en magisk lösning på alla dina frågeprestandaproblem. Precis som ett datalager som körs på traditionell SQL Server, kräver det övervakning och inställning av distributionsnycklar, index, cachning och uppdelning för att säkerställa bästa prestanda.
YTTERLIGARE ÖVERVÄGANDE
TimeXtender började stödja Azure Synapse som en måldatabas i version 19.11.2. Den här funktionen möjliggör användning av Azure Synapse Analytics som måldatalager eller iscensättningsdatabas. När de också är anslutna till Azure Data Lake via ODX-servern kan användare helt enkelt dra och släppa data från Data Lake till en Synapse SQL Pool med TimeXtender.
Vill du veta hur man automatiserar processer som kan samla olika datakällor i en plattform?