
Nästa skifte av transformationen handlar om att ”bli smart”. Allt från glödlampor till förarlösa lastbilar till hela städer kommer bli “smarta”, autonoma och uppkopplade i molnet. Artificial Intelligence (AI) och Machine learning (ML) kommer vara den primära drivkraften för ekonomisk tillväxt under det kommande decenniet i vad som kallas ”Machine Economy”.
För att förstå omfattningen av denna förändring måste man förstå att Artificial Intelligence (AI), Machine learning (ML) och Smart Automation kommer att driva 70 % av BNP-tillväxten under det kommande decenniet.
Beslutsfattande genom ML och AI kommer att vara den primära drivkraften för ekonomisk tillväxt under det kommande decenniet i vad som kallas ”Machine Economy”.
Data = hjärtat i ”Machine Economy”
Maskinekonomin kommer inte bara att vara beroende av data för att fungera, utan alla dessa smarta maskiner och anslutna enheter kommer att fortsätta generera exponentiellt ökande mängder data.
Organisationer skapar redan olika typer av intelligenta maskiner, allt från AI-driven programvara och självbetjäningsassistenter, till smarta IoT-sensorer.
Ju smartare dessa maskiner blir, desto mer kan de göra för oss, särskilt när de börjar samverka med varandra autonomt för att utföra produktion och distribution, utan behov av mänsklig inblandning.
Inget av detta är dock möjligt utan data.
Företag och organisationer behöver anpassa sig och utveckla tillgången till tillförlitlig data för att driva innovation, effektivitet och tillväxt.
Det första steget i processen att leverera tillförlitlig data är att extrahera den från en mängd olika källor (databaser, CRM- och ERP-program, sociala medieplattformar, API:er, IoT-enheter, etc.).
All denna data måste samlas centralt, städas upp och förberedas för analys och AI/maskininlärning.
Denna process av datakonsolidering, rensning, transformation och rationalisering skapas vanligtvis med hjälp av tre primära komponenter:

- Data Lake: Insamling och lagring av all rådata. Den kan användas av Data Scientists för avancerade analysändamål med hjälp av AI och maskininlärning.
- Data Warehouse: Används för att bearbeta, rensa och färdigställa data för analys.
- Data Marts/Products: Förser affärsutvecklare med data baserat på deras specifika användningsområde (kundanalys, försäljningsanalys, ekonomi, etc.)
Den infrastruktur som hanterar all data i en organisation brukar kallas Data Estate, (dataegendom).
Man syftar på databaser och data som finns i applikationer och i arkiv. Även den hårdvara och servrar som lagrar och överför och tillgängliggör data i användargränssnitt ingår i begreppet. Så även molntjänster.
Datadrivna organisationer kommer att vinna (igen).
De mest framgångsrika organisationerna under det senaste decenniet var de med bäst data.
Enligt McKinsey Global Institute var det inte bara 23 gånger större sannolikhet för datadrivna organisationer att få kunder, de var också 6 gånger mer benägna att behålla kunder och 19 gånger större sannolikhet att de var lönsamma.
Datadrivna organisationer hade enorma fördelar gentemot sina konkurrenter, eftersom de snabbt kunde:
- Upptäcka branschtrender och nya affärsmöjligheter.
- Förutse kundernas behov och skapa bättre produkter.
- Optimera produktivitet, prestanda och resursallokering.
Dataanalysfunktioner är nu grundinsatsen – baskostnaden för att göra affärer – oavsett din bransch eller företagsstorlek.
Hinder för att bygga en modern Data Estate
Tyvärr finns det betydande hinder som kan stoppa processen med att bygga ett modernt Data Estate:
• Exploderande datavolymer: Som vi redan har sett upplever organisationer en explosion i både mängden och typen av data som behöver samlas in, lagras och bearbetas från ett växande antal källor.
• En stor backlog av förfrågningar: Affärsteam är oftast fler än organisationens datateam, vilket leder till en oändlig eftersläpning av analysförfrågningar. En fjärdedel av de anställda på affärssidan medger att de har gett upp att få ett svar de behövde eftersom förberedelsen och analysen av data tog för lång tid.
• Personalbrist inom data- och analys. :Efterfrågan på data- och analyskunskaper överträffar utbudet, vilket gör att många företag kämpar för att hitta tillräckligt med talanger.
•Konstant uppdatering av kompetens: Data- och analytikermedarbetare är under konstant press att spendera den lilla lediga tiden de har på att lära sig de senaste teknologierna, verktygen och metoderna så att de kan uppdatera sina färdigheter och bevara sitt marknadsvärde.
• Utbrändhet: Datateamet tvingas ofta lägga betydande mängder tid på manuella, repetitiva databeredningsuppgifter, vilket kan leda till utbrändhet och hög omsättning. 79 % av dataproffs har övervägt att lämna branschen helt.
• Datakvalitet, säkerhet och efterlevnad: 95 % av dataexperterna rapporterar rädslor eller oro kring kontroll av åtkomst till känslig data, oavsiktlig radering av data, fel vid analys av data som leder till dåligt beslutsfattande, säkerhetsöverträdelser och problem med regelefterlevnad.
• Kommunikationsbarriärer: Även med ett starkt datateam på plats skapar kommunikationsbarriärer mellan affärsexperter och datateamet ofta ytterligare flaskhalsar och avmattningar. 34 % av affärsexperterna medger att de inte är säkra på sin förmåga att formulera sina datafrågor eller behov till datateamet.
Dessa problem kan orsaka flaskhalsar och frustration, hämma tillväxten och göra avsevärd skada på hela din organisation.
Räcker det med Data Management?
Du ska inte tvingas spendera månader på att handkoda ömtåliga pipelines mellan varje komponent i ditt datalandskap med hjälp av en komplex hög med verktyg.
Vi tror inte heller på dåligt integrerade ”dataplattformar” som inför strikta kontroller och låser in dig i ett eget ekosystem.
Det är uppenbart att dessa gamla metoder för datahantering helt enkelt inte kan möta behoven hos moderna datateam. Maskinekonomins snabba takt tillåter inte de flaskhalsar, avmattningar och begränsningar som dessa tillvägagångssätt medför.
Hela status quo för ”datahantering”-branschen är ålderdomlig, betungande och förtryckande, och vi anser att den bör avskaffas.
Dataexperter runt om i världen är i desperat behov av ett snabbare, smartare och mer flexibelt sätt att bygga och hantera sina dataområden.
Low-code, agil funktionalitet och integrationsmöjligheter
TimeXtender har tagit fasta på behovet av snabbare, smartare och mer flexibla sätt att bygga och hantera dataområden och att det dataexperter behöver är en lösning som tillhandahåller byggstenar beståendes av low-code.
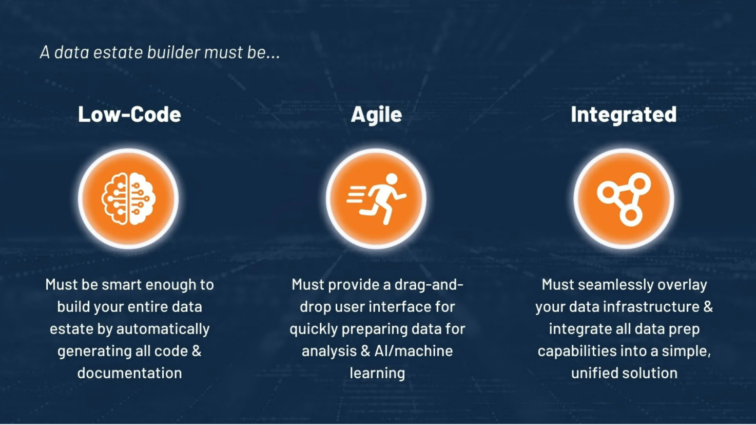
En sådan lösning måste uppfylla samtliga tre kriterier:
Low-code: Den behöver vara smart nog att kunna bygga en hel ”Data estate” genom att från start till slut automatisk generera all den underliggande koden och dokumentationen.
Agil funktionalitet: Den måste ge både tekniska utvecklare och affärsanvändare ett gränssnitt med drag-and-drop funktionalitet för att tillgodose behoven om att snabbt inta, förbereda och leverera data för analys och AI/maskininlärning.
Integrerad: Den behöver tveklöst överlappa med din nuvarande datainfrastruktur, utan att skapa en lösningslåsning, samtidigt som den integrerar alla data, förberedelser, kvalitet, säkerhet samt de styrningsmöjligheter som behövs. Allt detta i en enkel, enhetlig och metadatadriven lösning.
Hej då Data Management – välkommen Data Empowerment
Genom att göra det komplexa enkelt och automatisera allt som kan automatisera, är TimeXtenders mål att frigöra miljontals resurstimmar som istället kan användas för att utföra det som betyder mest och förändra världen. Det är så ett vinnande koncept ser ut i ”Machine Economy”.
Hur TimeXtender accelererar resan till Data Empowerment
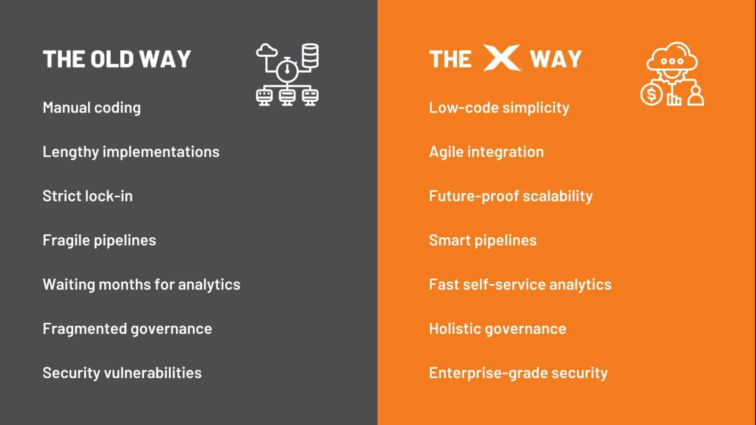
Low-Code: TimeXtender har en enkel drag-and-drop lösning för att kunna läsa in data och förbereda den för konsumtion. Utvecklingsteamen slipper manuella och repetetiva uppgifter. Kod och dokumentation genereras automatiskt och minskar utvecklingskostnaden med upp till 70 %.
I de fall där koden behöver anpassas manuellt finns fortfarande möjligheten till detta.
Agil integration: TimeXtender kan idag ansluta till mer än 250 datakällor. Integrationen blir agil, innehåller mindre kod, (low-code) och blir enhetlig. Fortfarande med full kontroll över hur data är lagrad och produktionssatt.
Framtidssäkrad skalbarhet: Eftersom TimeXtender är oberoende av datakällor, lagringstjänster och visualiseringsverktyg kan du eliminera inlåsning i lösningen. Du kan säkerställa att din datainfrastruktur är mycket skalbar för att möta framtida analyskrav. Med TimeXtender kan du snabbt anamma ny teknik och implementeringsmodeller, förbereda data för AI och maskininlärning och migrera till molnplattformar med ett klick.
Smartare pipelines: När oväntade förändringar inträffar kan ömtåliga pipelines lätt gå sönder och måste felsökas manuellt. Med vårt metadatabaserade tillvägagångssätt, närhelst en förändring i dina datakällor eller system görs, kan du omedelbart sprida dessa ändringar över hela pipelinen med bara några få klick. Dessutom tillhandahåller TimeXtender inbyggda datakvalitetsregler, varningar och konsekvensanalyser, samtidigt som man utnyttjar maskininlärning för att driva vår Intelligent Execution Engine och prestandarekommendationer.
Självbetjäningsanalys: Vår lågkodsteknologi, dra-och-släpp-gränssnitt och Semantiska Lager möjliggör snabbt skapande och modifiering av dataprodukter, utan att kräva omfattande datateknik-kunskaper. Dessa dataprodukter kan skapas av BI- och analysexperter en gång och sedan distribueras till flera visualiseringsverktyg (som Power BI, Qlik eller Tableau) för att snabbt generera grafer, instrumentpaneler och rapporter.
Holistisk styrning: Vårt metadatabaserade tillvägagångssätt möjliggör snygg organisation av dina dataprojekt, samtidigt som den tillhandahåller end-to-end-dokumentation, datalinjevisualisering och versionskontroll över flera miljöer. Genom att använda metadata för att driva modellen och distribuera koden kräver TimeXtender aldrig någon åtkomst eller kontroll över dina faktiska data, vilket eliminerar säkerhetssårbarheter och efterlevnadsproblem, samtidigt som du får en helhetsbild av vad som händer i hela din dataanläggning.
Enterprise-Grade Security: TimeXtenders säkerhetsfunktioner låter dig ge användare tillgång till känslig data, samtidigt som datasäkerhet och kvalitet bibehålls. Du kan enkelt skapa databasroller och sedan begränsa åtkomsten till specifika vyer, scheman, tabeller och kolumner (behörigheter på objektnivå) eller specifika data i en tabell (behörigheter på datanivå). Vår säkerhetsdesignstrategi låter dig skapa en säkerhetsmodell och återanvända den på valfritt antal tabeller.
Förtroende och support: Som en Microsoft Gold-certifierad partner har vi 15+ års erfarenhet av att bygga moderna datalösningar för över 3 300 organisationer med en oöverträffad retentionsgrad på 97 %. När du väljer TimeXtender, kommer en av våra utvalda partners att få dig att ställa in snabbt och hjälpa dig att utveckla en datastrategi som maximerar resultaten, med kontinuerligt stöd från våra kundframgångs- och lösningsspecialistteam. Vi tillhandahåller också en onlineakademi, omfattande certifieringar och bloggartiklar varje vecka för att hjälpa hela ditt team att ligga steget före när du växer.
Vill du veta hur vi på Visma bWise kan hjälpa ert företag eller organisation att bli mer datadrivna och fatta smarta beslut?